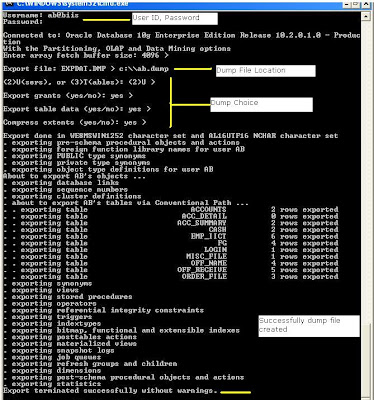
How decorator pattern works
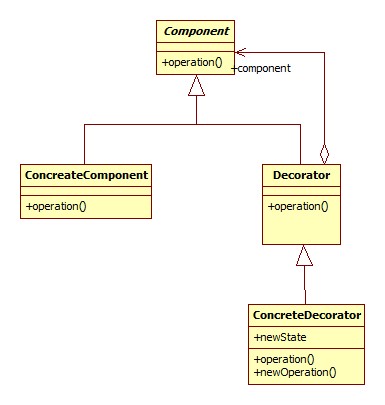
Decorator is a structural pattern that adds additional responsibility to the object at run time. This pattern adds responsibility to a particular object not on the class. As a result different object of same type can have different responsibilities. I would explain a real life example from my experience. I am a biker. Every morning I go to office riding on my bike. When I bought this bike the seller just sold the standard bike to me. They didn't provide any tail light, head light, mud guard and even the kickstand with the bike. Later I added or decorated my bike by adding a tail light, mud guard and with a kickstand. So, functionality of each of this component is different. I added them with my bike and they are responsible for additional functionalities. This can be thought of as a decorator pattern example. Here first I have the bike with standard installation. Then I decorated it with other component. Participants in a decorator pattern are Component interface a Conc